Easy??
These are the things I thought would be easy!
Docker/Linux
To simplify switching between cloud providers, I decided to run my web server on Linux and manage dependencies with Docker. Should be simple, right?
Everything started off well. The app worked perfectly on my local Linux VM, but when I ran it on the Alpine Linux container that I wanted to use for production, every cron job failed.
I assumed all Linux distributions handled cron in a similar manner, but after searching through Linux forums, I learned that’s not the case! I needed to rewrite all of my cron jobs specifically for the Alpine Linux distribution that I wanted to use in production.
(whenever I’m searching for solutions by reading Linux wikis, something has gone horribly wrong)

After the rewrite, my cron jobs were now running correctly, but sadly my Docker issues were just beginning.
I chose Alpine Linux for my Docker container, because I read multiple reviews praising Alpine for being highly secure, fast, and small. Unfortunately, it turned out to be the absolute worst distribution for my use case.
After adding the python dependencies, the Docker build time jumped from 30 seconds to 40 minutes. Excruciatingly slow! I thought I must’ve configured something incorrectly, but I couldn’t find any mistakes. After some desperate google-ing, I found an article with the answer -- python and Alpine Linux integrate terribly.
Apparently, Alpine Linux is one of the few Linux distributions that uses the MUSL version of the C library. MUSL isn’t compatible with the current python distribution system, so when using Alpine you must compile all the C code in the python packages on every rebuild (which takes absolutely forever). This was theoretically fixed by PEP 656, but the changes haven’t rolled down to the relevant projects yet.
I eventually switched to a different Linux distro and re-wrote all my cron scripts again for the third time!
GO
In programmer forums, people love to talk about how easy GO is to learn. That they mastered GO in under an hour, how concurrency in GO is trivial, etc.
My core programming languages are in the python/javascript realm, but I needed to learn GO for a work project. Based on what I’d heard from others, I expected to pick it up super quickly.
However, once I started using the language, I was a little surprised how many low-level details GO requires you to think about when implementing rather basic things.
For example, in python and javascript, working with JSON is super easy - there are built-in functions and features that handle most of the grunt work for you. In contrast, when dealing with JSON in GO, here is a list of things that you need to understand well:
-pointers
-references
-nested structs
-interfaces
-reflection
None of these are incredibly difficult to implement, but I think it’s emblematic of the complexity you encounter once you start building actual apps. I’ve never needed to worry about introducing pointer bugs when parsing JSON before!
Concurrency in GO was also a little more involved than I expected. GO really does provide good tools to handle concurrency, but concurrency is still a hard problem. From the way people said GO makes concurrency trivial, I expected GO to completely eliminate certain types of concurrency issues. However, I still need to watch out for the same concurrency bugs (deadlocks, race conditions, etc.) as in other languages.
I actually need to spend much more time thinking about these types of bugs in GO, because I’m implementing many of these concurrency solutions from scratch myself (compared to other languages, libraries seem to be somewhat frowned upon in GO). As a developer, I enjoy building from scratch, but I do wonder if it’s the most productive use of my time.
GO is a great language, it just wasn’t as ‘easy’ as I expected. Perhaps I would think differently if I was coming from a C++ background!
Amazon Web Services
AWS is fairly straightforward, but only if you follow the ‘golden path’. As soon as you stray from the most common patterns, things can get rather complicated.
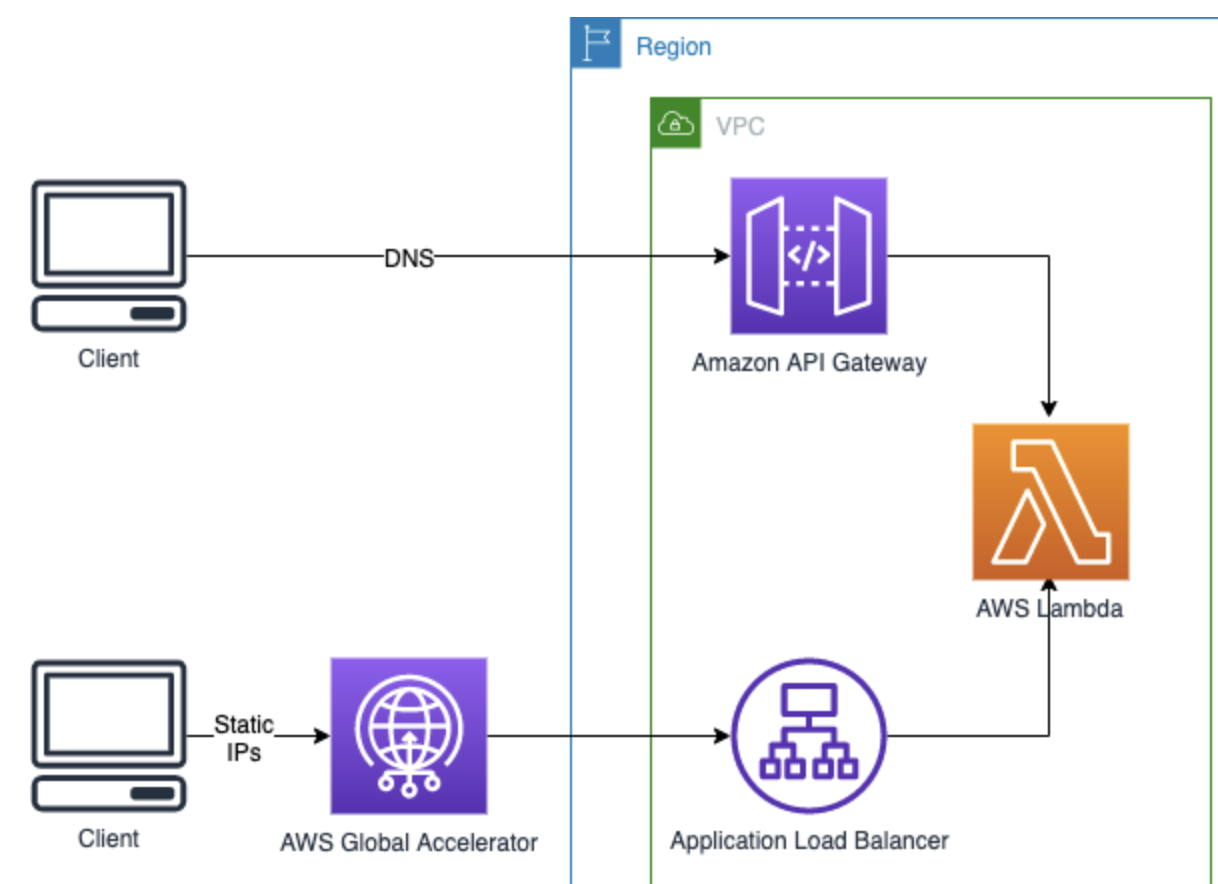
For example, I often use AWS Lambda because it’s cheap, fast, and dead simple. But, for one project, security requirements dictated that we assign a static IP address to our AWS Lambda service (dynamic is the default).
AWS does provide documentation on how to create a static IP address, but it involves adding Gateways, Load Balancers, and a whole host of other things. Unfortunately, this added complexity increases latency and cost, which sort of defeats the purpose of using Lambda in the first place.
Whenever I look up how to do something in AWS and the answer is to connect like six other AWS services, I cry a little bit inside.
Conclusion
These projects were a little more difficult than I expected, but were great learning experiences. Sometimes we must trick ourselves into being ambitious :)